En tant que référenceurs, nous savons beaucoup de choses sur Google. Les mises à jour de l’algorithme sont généralement basées sur des brevets publiés. Le but fondamental des mises à jour est destiné à éliminer les pratiques de référencement douteuses.
Par pratiques douteuses, on entend, toute pratique qui tente d’exploiter des failles dans l’algorithme de Google afin d’obtenir un meilleur classement dans les moteurs de recherche. Google pénalise les sites Web qui le font, car le contenu fourni aux utilisateurs sur leurs pages de résultats de recherche est généralement de qualité médiocre, ce qui signifie que les résultats du moteur de recherche en souffrent également.
Tous ceux qui jouent au jeu du référencement naturel depuis plusieurs années connaissent bien les principales tactiques Black hat que Google pénalise (nous verrons certains exemples concrets plus bas dans l’article).
🚀 Lecture express : 3 brevets Google à connaître pour éviter une pénalité SEO
- Brevet du 8 octobre 2013 concernant le "content spinning" : réécriture automatique de pages identiques pour éviter le contenu dupliqué.
- Brevet du 13 décembre 2011 concernant le "keyword stuffing" : bourrage de mot-clé pour positonner un site sur un seul mot.
- Brevet du 5 mars 2013 concernant le "cloaking" : camouflage de contenu pour tromper l'algorithme.
Pour tout savoir sur ces brevets Google et découvrir des exemples concrets de pénalités liées à ceux-ci, il vous suffit de lire la suite 😉.
❓ Pourquoi la manière dont Google identifie les tactiques Black Hat est-elle importante?
Parce que vous ne voulez ne pas commettre accidentellement des erreurs de SEO qui ont pour conséquence que Google vous pénalise ! Ils penseront que vous essayez de tirer parti du système.
En fait, vous avez simplement commis quelques erreurs de référencement coûteuses car vous ne le saviez pas. Pour mieux comprendre comment l'algorithme de Google identifie les mauvaises pratiques de référencement (et ainsi mieux comprendre comment éviter de commettre des erreurs de référencement), vous devez passer en revue les brevets de Google concernant certaines des tactiques les plus courantes de black hat.
💫 Content spinning
Le brevet en question : « Identifying gibberish content in resources » (patent 8 octobre 2013)[1]
Le content spinning est souvent utilisé pour des fins de link buiding.
Un site Web va réécrire une même publication des centaines de fois dans le but d’augmenter son nombre de liens et son trafic, tout en évitant qu’elle soit considérée comme du contenu dupliqué. Certains sites réussissent même à générer des revenus grâce à ce type de contenus, par le biais de liens publicitaires.
Toutefois, étant donné que la réécriture de contenu est une tâche assez fastidieuse, beaucoup de sites se tournent vers des logiciels de rédaction automatique capables de remplacer automatiquement les noms et les verbes. Cela se traduit généralement par la création de contenus de très mauvaise qualité ou, en d’autres termes, du charabia.
Le brevet explique comment Google repère ce type de contenu grâce à l’identification des phrases incompréhensibles ou incorrectes contenues dans une page Web. Le système qu’utilise Google se base sur différents facteurs afin d’attribuer à la page une note contextuelle : il s’agit du « gibberish score », littéralement le score de charabia.
Google utilise un modèle de langue qui est capable de reconnaitre lorsqu’une suite de mots est artificielle. En effet, il identifie et analyse les différents n-grams sur une page et les compare à d’autres groupements n-gram sur d’autres sites Web. Un n-gram est une séquence contiguë d’éléments (ici des mots).
À partir de là, Google génère un score de modèle de langue et un score « query stuffing ». Il s’agit de la fréquence de répétition de certains termes dans le contenu. Ces scores sont ensuite combinés pour calculer le gibberish score. Ce dernier est ensuite analysé afin de déterminer si la position du contenu dans la page de résultats doit être modifiée.
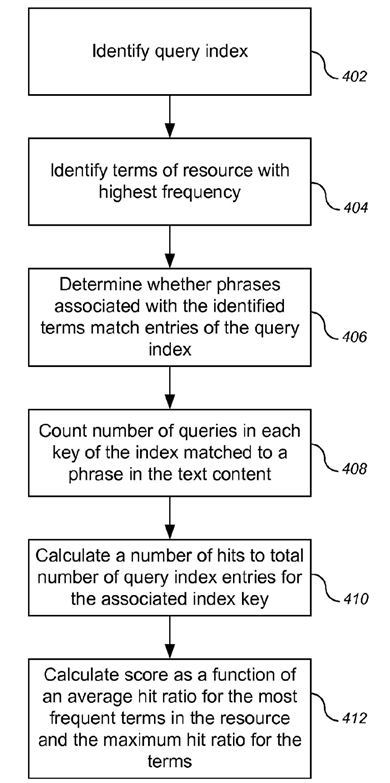
Bien que le brevet ne précise pas explicitement que ce système vise à pénaliser les articles spinnés, ces derniers contiennent souvent beaucoup de charabia et sont donc les premiers à être sanctionnés.
🔑 Keyword Stuffing (bourrage de mots-clés)
Le brevet en question : « Detecting spam documents in a phrase based information retrieval system » (13 décembre 2011)[2]
Le keyword stuffing est l’une des plus anciennes pratiques dites « black hat ». Il s’agit de l’utilisation superflue de nombreux mots-clés dans le but d’améliorer le référencement d’un contenu.
À une certaine époque, beaucoup de pages contenaient peu voire aucune information utile, car elles enchaînaient les mots-clés, sans se soucier du sens des phrases. La mise à jour de son algorithme a permis à Google de mettre un frein à cette stratégie.
Le brevet
La manière dont Google indexe les pages en se basant sur des phrases complètes est extrêmement complexe. Aborder ce brevet (qui n’est d’ailleurs pas le seul sur ce sujet) est un premier pas vers la compréhension de l’impact des mots-clés sur l’indexation.
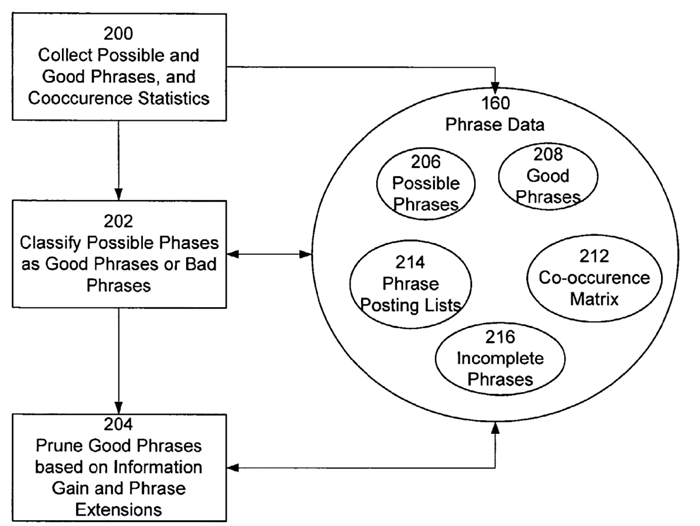
Le système de Google qui permet la compréhension des phrases peut être décomposé en trois étapes :
- Le système recueille les expressions utilisées ainsi que les statistiques relatives à leur fréquence et à leur co-occurence.
- Il les classe ensuite comme étant bonnes ou mauvaises en fonction des statistiques de fréquence qu’il a recueillies.
- Enfin, en utilisant la mesure prédictive que le système a établie depuis les statistiques liées à la co-occurence des mots, il affine le contenu de la liste d’expressions considérées comme bonnes.
Le technologie utilisée par Google pour accomplir ces étapes peuvent provoquer des migraines ! C’est pourquoi nous allons aller droit au but.
En quoi ce système permet-il à Google d’identifier les cas de keyword stuffing ?
En plus d’être en mesure de déterminer combien de mots-clés sont utilisés dans un document donné (évidemment, un document dont la densité de mots-clés est de 50 % relève du keyword stuffing), Google est également capable de mesurer le nombre d’expressions liées à un mot-clé (ce sont les mots-clés LSI).
Un document normal possède généralement entre 8 et 20 phrases connexes, selon Google, contre 100 voire jusqu’à 1 000, pour un document utilisant des méthodes de spam.
En comparant les statistiques des documents qui utilisent les mêmes requêtes cléset expressions connexes, Google peut déterminer si un document emploie un plus grand nombre de mots-clés et d’expressions connexes que la moyenne.
Le keyword stuffing est l’une des erreurs SEO les plus graves. Heureusement, elle est relativement facile à éviter. Ne vous focalisez pas sur les mots-clés, mais sur la qualité de votre contenu. Vous devriez ainsi éviter d’être pénalisé.

🕵️♂️ Cloaking
Le brevet en question : « Systems and methods for detecting hidden text and hidden links » (5 mars 2013)[3]
Le cloaking permet de tromper l’algorithme du moteur de recherche en déguisant une page.
Cela permet à un site Web d’être référencé comme étant quelque chose qu’il n’est pas. Imaginez un déguisement qui autorise un site à se faufiler parmi les résultats de recherche. Il ne sera découvert que si un utilisateur clique dessus et constate une différence.
Il existe un certain nombre de façons différentes de cloaker un site Web. Vous pouvez :
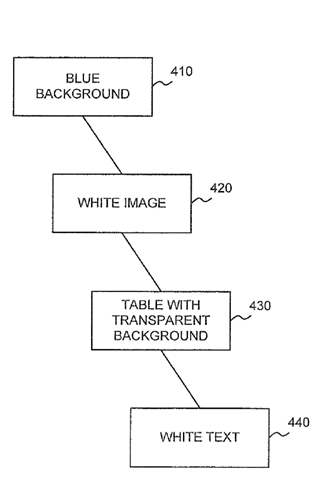
- utiliser un texte blanc sur fond blanc ;
- placer du texte derrière une image ou une vidéo ;
- définir la taille de votre police à 0 ;
- cacher les liens en les insérant dans un seul caractère (un trait d’union entre deux mots par exemple) ;
- utiliser les CSS pour positionner votre texte hors de l’écran...
Ces tactiques de dissimulation permettent d’augmenter artificiellement le référencement d’une page. Ainsi, il est possible de placer une liste de mots-clés sans rapport avec le sujet de la publication en bas de la page en blanc sur fond blanc.
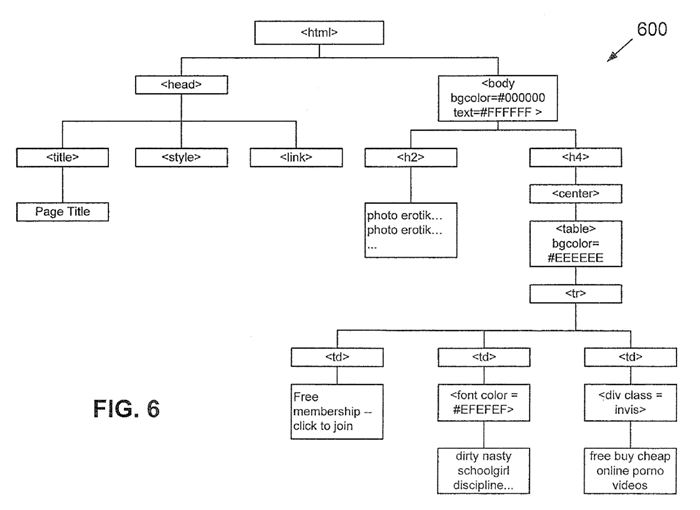
Dans son brevet, Google explique que son système peut découvrir ce type de supercheries en inspectant le Document Object Model (DOM).
Le DOM d’une page permet à Google de récolter des informations concernant les différents éléments de la page. Sont compris : la taille du texte, la couleur du texte, la couleur de l’arrière-plan, la position du texte, l’ordre des calques et la visibilité du texte.
Le système, en analysant le DOM, s’apercevra que vous avez essayé de cloaker votre site Web afin de tromper le moteur de recherche.
👀 Exemples de sanctions SEO encourues liées aux brevets Google
Les erreurs décrites plus haut, qu’elles soient intentionnelles ou accidentelles, vous exposent à des sanctions sévères.
Google ne prend en compte ni la taille ni la notoriété du site internet et pénalise tous les utilisateurs qui enfreignent les règles. Ils se sont d’ailleurs déjà pénalisés eux-mêmes !
Voici quelques exemples de sanctions administrées à des sites internet de renom.
Rap Genius
Le site américain qui répertorie les paroles des chansons de rap a demandé à des blogueurs d’insérer des liens renvoyant vers leur site. En échange, ils promettent de tweeter les publications des blogueurs.
Cela constitue une ferme de liens et Google a rapidement pénalisé le site Web. Le site a été retiré de la première page des résultats, et ce, sur toutes les expressions clés — y compris son propre nom ! La sanction a duré dix jours.
BMW
BMW commet une grosse erreur en décidant d’utiliser le cloaking pour améliorer son référencement. Cela se passe en 2006 et, même à l’époque, Google réussit à constater l’infraction. Les marques reconnues comme BMW ne sont donc pas exemptes de sanctions. Son site Web a ainsi été désindexé pendant trois jours. Il s’agit, pour une marque de cette taille, d’une pénalité énorme qui endommagea l’image de la société.
JCPenney
Des achats de liens par la société JC Penney ont été découverts par un journaliste du New York Times. Ce dernier a en effet remarqué que chacune des pages était extrêmement bien positionnée. La plupart de leurs contenus ont été retirés de la première page. Cette sanction a duré pendant 90 jours. Leur trafic a chuté de plus de 90 %. JC Penney s’est empressé de licencier la société en charge de son référencement et a nettoyé son site Web.
Google Japon
Ce n’est donc pas une blague. Google s’est bien sanctionné lui-même. Il s’est avéré que Google Japon achetait des liens afin de promouvoir Google widget. Sa sanction ? Son PageRank a été rétrogradé de PR9 à PR5 pour une période de 11 mois.
Google prend le SEO très au sérieux et n’a aucun scrupule à imposer des sanctions aux entreprises qui utilisent des tactiques black hat.
Ce type de stratégies SEO peut entraîner des sanctions, dont la rétrogradation du PageRank, le retrait de la première page et même la désindexation totale du site Web, selon la gravité de la faute.
🎬 Conclusion
En faisant le point sur ces brevets, vous êtes maintenant en possession d'infomations cruciales pour éviter une pénalité Google. Bien entendu, certains référenceurs sont experts pour lire entre les lignes des brevets et autres recommandation de Google. Ainsi, leurs pratiques black hats continuent de fonctionner à l'heure actuelle. Mais jusqu'à quand ?
Les risques encourus en cas de mise à jour de l'algorithme ou de révision manuelle des données sont à mon avis trop importants pour continuer à agir ainsi. Par ailleurs, avec l'avènement de la recherche vocale et l'essor des requêtes de longue-traîne, le bourrage de mots-clés et le cloaking sont définitivement des actions qui ne valent plus la peine.
Bien entendu, pour que votre stratégie SEO soit rentable, cela demande du temps, de l'application et de l'investissement (en temps et en argent). Et spécialement si votre domaine est très concurrentiel ! Toutefois, il existe aujourd'hui des techniques white hats et respectueuses de l'internaute qui permettent de vous faire une place dans la SERP :
- respectez les préconisations de Google (particulièrement les critères EAT),
- engagez des rédacteurs web formés au SEO,
- faites-vous accompagner par des consultants en référencement qui ne vous promettent pas monts et merveilles en quelques semaines.
🙏 Sources utilisées pour rédiger cet article
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: