Todas as ferramentas de análise semântica utilizam a extração de palavras-chave para criar guias de redação. Usar o método de extração correto, de acordo com o objetivo, permite encontrar os termos mais relevantes para a redação de SEO.
A extração de palavras-chave (também chamada de análise de palavras-chave) é um método de estudo de um texto que consiste em extrair automaticamente as palavras e termos mais importantes. Isso permite resumir o conteúdo de um texto e identificar os principais tópicos abordados.
A extração de palavras-chave ajuda os motores de busca a analisar o conteúdo das páginas online. Permite classificar o conjunto de dados e definir as palavras que descrevem melhor cada página. Assim, o Google cria clusters (agrupamentos) de palavras-chave, economizando muitas horas de processamento se tivesse que consultar a totalidade do seu índice a cada pesquisa.
Uma das principais tarefas do SEO é determinar quais são as palavras-chave estratégicas que queremos direcionar em nosso site, a fim de criar conteúdo em torno dessas palavras-chave.
Este artigo utiliza exemplos e referências do universo Stargate SG-1 :)

❓ Para que serve a extração de palavras-chave em SEO?
Existem pelo menos 3 boas razões para pesquisar as palavras-chave de uma página!
- Conhecer as opiniões
- Monitorar a concorrência
- Encontrar novas ideias
1. Extrair palavras-chave e opiniões de uma página
Captura de tela da ferramenta SEOQuantum
Primeiro, vamos analisar a avaliação de uma página sobre a série Stargate. Graças à extração de palavras-chave, é fácil saber quais opiniões são mencionadas (coerente; série notável; promissora...).
Você pode usar o software SEOQuantum para extrair palavras-chave de um texto para encontrar palavras isoladas (palavras-chave) ou grupos de duas ou mais palavras que formam uma frase (frases-chave).
2. Monitorar a concorrência
Existem inúmeras ferramentas disponíveis para pesquisa de palavras-chave. No entanto, você também pode aproveitar a extração de palavras-chave para navegar automaticamente pelo conteúdo dos sites e extrair suas palavras-chave mais frequentes. Se você identificar as palavras-chave mais relevantes usadas por seus concorrentes, por exemplo, pode encontrar excelentes oportunidades para criar conteúdo.
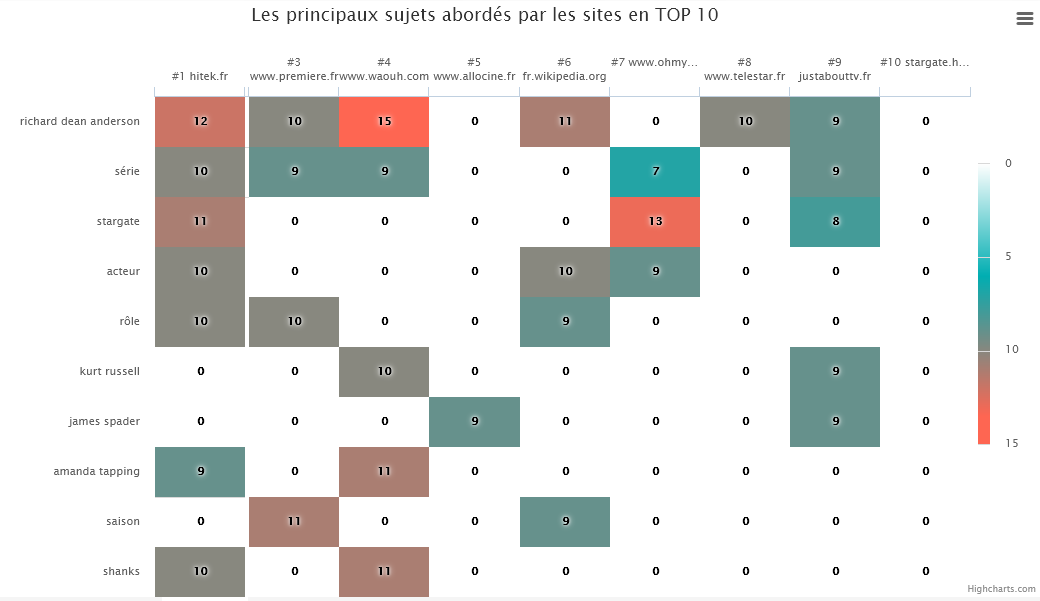
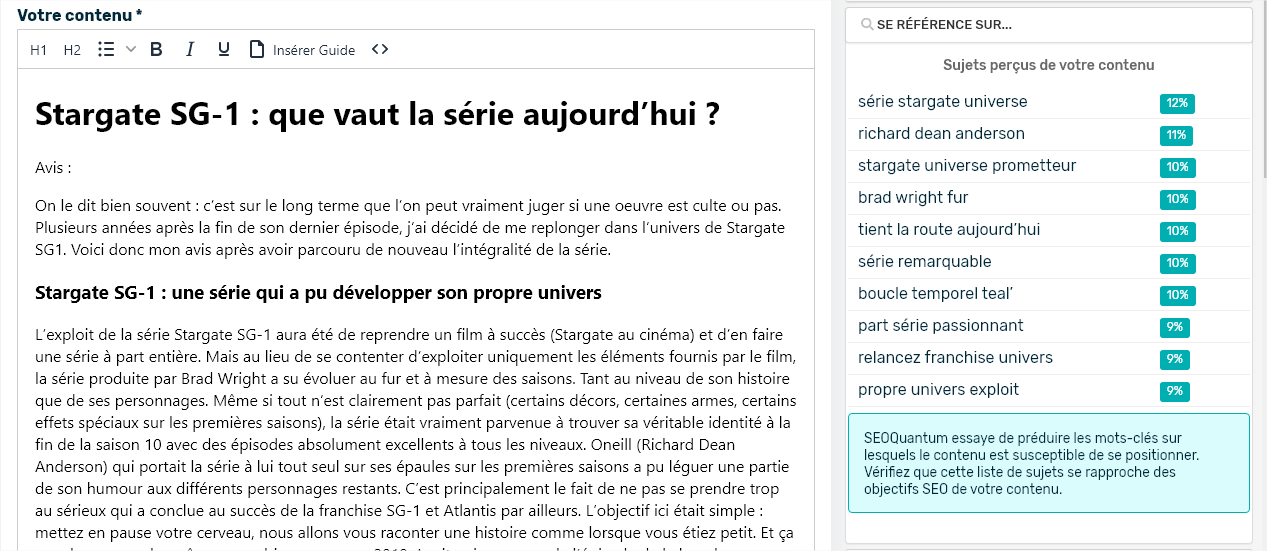
Graças à análise da concorrência do SEOQuantum, adoro este gráfico (heatmap) que permite ver num piscar de olhos os tópicos abordados pelos concorrentes no TOP 10 da SERP.
Aqui, para a consulta "atores stargate", notamos que:
- O primeiro site posicionado aborda principalmente a série e os principais atores (Richard Dean Anderson, Amanda Tapping, Michael Shanks)
- os outros tópicos das páginas da SERP são direcionados para a série ou para os atores do primeiro filme (Kurt Russel e James Spader).
3. Encontrar novas ideias de palavras-chave
As opiniões sobre produtos e outros tipos de conteúdo gerado pelos usuários podem ser excelentes fontes para descobrir novas palavras-chave. Extrair palavras-chave para identificar palavras-chave estratégicas junto aos consumidores pode ser usado para fins de SEO por meio de estratégias de cauda longa.
Como você pode ver, as palavras-chave já estão presentes no texto original. Essa é a principal diferença entre a extração de palavras-chave e o modelagem de tópicos[1], que consiste em escolher palavras-chave em uma lista de vocabulário ou categorizar um texto com base nas palavras-chave usadas.
🤔 Como a extração de palavras-chave é útil?
Se considerarmos que mais de 80% dos dados que geramos diariamente não são estruturados - ou seja, não estão organizados de forma predefinida e, portanto, são difíceis de analisar e processar - a extração de palavras-chave é muito atraente. É uma ferramenta poderosa que pode ajudar a entender os dados sobre uma página, opiniões de clientes, um comentário... Enfim, todos os dados não estruturados.
Entre as grandes vantagens da extração de palavras-chave, podemos citar:
Escalabilidade
A extração automatizada de palavras-chave permite que você analise tantos dados quanto desejar. Claro, você poderia ler os textos você mesmo e identificar os termos-chave manualmente, mas isso levaria muito tempo. A automação dessa tarefa dá a você a liberdade de se concentrar em outras tarefas.
Critérios consistentes
A extração de palavras-chave age com base em regras e parâmetros predefinidos. Você não terá inconsistências. Estas são comuns quando a análise do texto é manual.
Análise em tempo real
Você pode realizar uma extração de palavras-chave em publicações nas redes sociais, opiniões de clientes ou tickets de suporte ao cliente e obter informações sobre o que está sendo dito sobre seu produto em tempo real.
Em resumo...
A extração de palavras-chave permite extrair o que é relevante de uma grande quantidade de dados não estruturados. Ao extrair palavras ou frases-chave, você poderá ter uma ideia das palavras mais importantes de um texto e dos tópicos abordados.
Agora que você conhece o conceito de extração de palavras-chave e tem uma boa compreensão de seu uso, é hora de entender como ele funciona. A próxima seção explica os princípios fundamentais da extração de palavras-chave e apresenta as diferentes abordagens deste método, incluindo estatísticas, linguística e aprendizado de máquina.
🔎 Como funciona a extração de palavras-chave?
A extração de palavras-chave permite identificar facilmente as palavras e frases relevantes de um texto não estruturado. Isso inclui páginas da web, e-mails, publicações em redes sociais, conversas de mensagens instantâneas e qualquer outro tipo de dado que não esteja organizado de forma predefinida.
Existem diferentes métodos que você pode usar para extrair automaticamente as palavras-chave. Desde abordagens estatísticas simples que detectam palavras-chave contando a frequência das palavras, até abordagens mais avançadas possibilitadas pelo aprendizado de máquina, você poderá implementar o modelo que atenda às suas necessidades.
Nesta seção, examinaremos as diferentes abordagens de extração de palavras-chave, com foco nos modelos baseados em aprendizado de máquina.[2]
Abordagens estatísticas simples
O uso de estatísticas é um dos métodos mais simples para identificar palavras e expressões-chave em um texto.
Existem diferentes tipos de abordagens estatísticas, incluindo a frequência das palavras, colocações de palavras e coocorrências, o TF-IDF (do inglês term frequency-inverse document frequency) e o RAKE (Rapid Automatic Keyword Extraction).
Essas abordagens não exigem dados de treinamento para extrair as palavras-chave mais importantes de um texto. No entanto, como se baseiam em estatísticas, podem negligenciar palavras ou frases relevantes que são mencionadas apenas uma vez. Vamos examinar mais detalhadamente essas diferentes abordagens:
Frequência das palavras
A frequência das palavras consiste em listar as palavras e frases que aparecem com mais frequência em um texto. Isso pode ser muito útil para várias finalidades, desde a identificação de termos recorrentes em uma série de avaliações de produtos até a pesquisa dos problemas mais comuns nas interações com o atendimento ao cliente.
No entanto, as abordagens baseadas na frequência das palavras consideram os documentos como uma simples "coleção de palavras", ignorando aspectos cruciais relacionados à semântica, estrutura, gramática e ordem das palavras. Sinônimos, por exemplo, não podem ser detectados por este método.
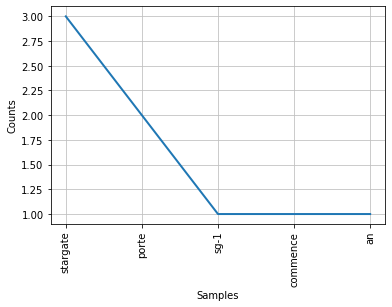
Aqui está um trecho do código Python para obter a frequência das palavras em um texto (você encontrará o notebook mais abaixo):
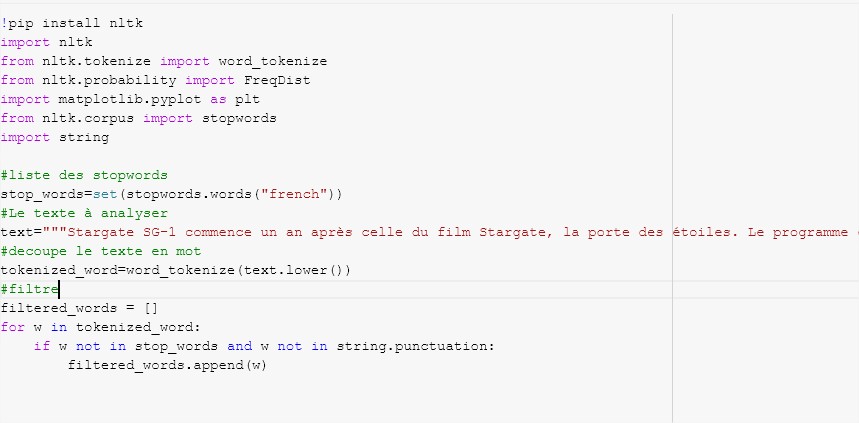

Colocações e coocorrências de palavras
Também conhecidas como n-gramas, as colocações de palavras e coocorrências podem ajudá-lo a entender a estrutura semântica de um texto. Esses métodos consideram cada palavra como única.
Diferenças entre colocações e coocorrências:
As colocações são palavras que são frequentemente associadas. Os tipos mais comuns de colocações são bigramas (dois termos que aparecem de forma adjacente, como "redação web" ou "agência digital") e trigramas (um grupo de três palavras, como "fácil de usar" ou "transporte público").
As coocorrências, por outro lado, referem-se a palavras que tendem a coexistir no mesmo texto. Elas não precisam necessariamente ser adjacentes, mas têm uma relação semântica.

O TF-IDF
TF-IDF é a abreviação do inglês term frequency-inverse document frequency, uma fórmula que mede a importância de uma palavra que aparece em um documento que faz parte de um corpus. Essa medida calcula o número de vezes que uma palavra aparece em um texto (term frequency) e compara-o com o inverso da proporção de documentos do corpus que contêm o termo (ou seja, a raridade ou frequência dessa palavra).
Ao multiplicar essas duas quantidades, obtemos uma pontuação TF-IDF. Quanto maior a pontuação, mais relevante é a palavra para o documento.
No que diz respeito à extração de palavras-chave, essa medida pode ajudá-lo a identificar as palavras mais relevantes de um conteúdo (aquelas que obtiveram as melhores pontuações) e considerá-las como palavras-chave. Isso pode ser particularmente útil para tarefas como a marcação de tickets de suporte técnico ou a análise de comentários de clientes.
Na maioria desses casos, as palavras que aparecem com mais frequência em um conjunto de documentos não são necessariamente as mais relevantes. Da mesma forma, uma palavra que aparece em um texto único, mas que não aparece em outros documentos, pode ser muito importante para entender o conteúdo desse texto.
TF IDF para SEO?
Os motores de busca às vezes usam o modelo TF-IDF em conjunto com outros fatores.
O método TF-IDF fornece informações suficientes para otimizar suas redações de conteúdo? De jeito nenhum.
Esta metodologia tem mais de 50 anos e desempenha um papel muito limitado no funcionamento dos algoritmos de pesquisa do Google. Não é uma tecnologia de ponta.
RAKE
O Rapid Automatic Keyword Extraction (RAKE) é um método bem conhecido de extração de palavras-chave que usa uma lista de palavras vazias (stopwords) e frases que atuam como "delimitadores" para detectar as palavras ou frases mais relevantes em um texto.
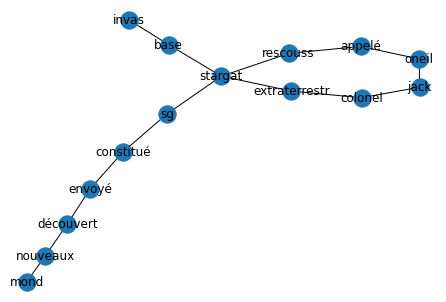
Considere o seguinte texto como exemplo:
Após a invasão da base Stargate por extraterrestres, o coronel Jack O'Neill é chamado para ajudar. Stargate SG-1 é então formado e enviado para descobrir todos esses novos mundos.
A primeira coisa que o método faz é dividir o texto em uma lista de palavras e remover as palavras vazias dessa lista. O resultado é uma lista contendo o que chamamos de palavras de conteúdo.
Suponha que nossa lista de palavras-chave e frases seja assim:
stopwords = [após, de, a, por, dos, o, não, se, ele, de, você, para, dos, a, um, elas, ….]
Nossa lista de 8 palavras de conteúdo será assim:
palavras_conteudo = [Invasão, base, stargate, extraterrestre, coronel, Jack Oneill, chamado, ajuda, Stargate, SG1, formado, enviado, descoberta, novos, mundos,…] com delimitador a vírgula ou o ponto.
Em seguida, o algoritmo divide o texto com base nas frases e palavras vazias para criar expressões. No nosso caso, as frases-chave seriam as seguintes:
Após a invasão da base Stargate por extraterrestres, o coronel Jack ONeill é chamado para ajudar. Stargate SG-1, é então formado pelo coronel e enviado para descobrir todos esses novos mundos.
Depois de dividir o texto dessa maneira, o algoritmo cria uma tabela de coocorrências de palavras. Cada linha indica o número de vezes que uma palavra de conteúdo específica coexiste com outra palavra de conteúdo.
Uma vez construída esta tabela, as palavras são pontuadas. As pontuações correspondem ao número de aparições de uma palavra na tabela (ou seja, a soma do número de coocorrências da palavra com qualquer outra palavra de conteúdo). Portanto, trata-se da frequência da palavra (ou seja, o número de vezes que a palavra aparece no texto).
Se dividirmos o grau dividido pela frequência de cada uma das palavras do nosso exemplo, obteríamos:
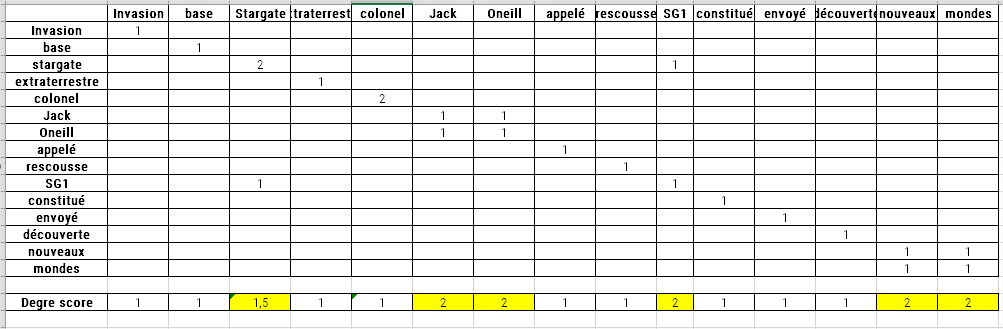
Se duas palavras ou frases-chave aparecerem juntas na mesma ordem mais de duas vezes, uma nova frase-chave é criada, independentemente do número de palavras vazias que ela contém. A pontuação desta frase-chave é levada em consideração da mesma forma que a das frases-chave únicas.
Uma palavra-chave ou frase-chave é selecionada quando sua pontuação está entre as T melhores pontuações, sendo T o número de palavras-chave que você deseja extrair.
Exemplo com RAKE NLTK
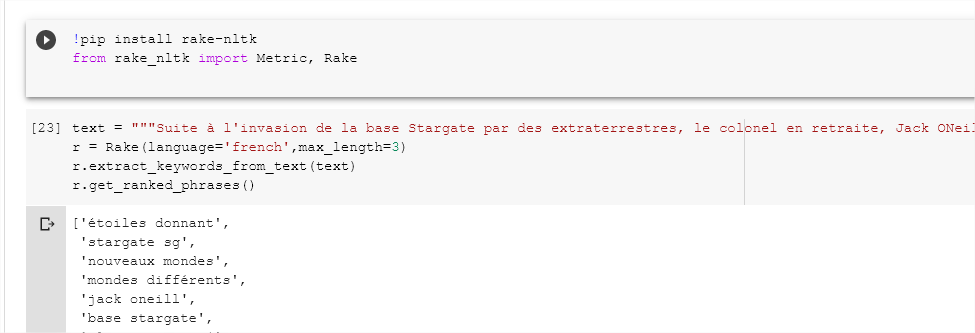
RAKE NLTK é uma implementação específica em Python do algoritmo RAKE (Rapid Automatic Keyword Extraction) que utiliza o NLTK por baixo dos panos. Isso facilita o uso para outras tarefas de análise de texto.
Abordagens baseadas na teoria dos grafos
Um grafo pode ser definido como um conjunto de vértices com conexões entre eles. Um texto é então representado como um grafo de várias maneiras. As palavras podem ser consideradas como vértices que são conectados por uma aresta direcionada (ou seja, uma conexão unidirecional entre os vértices).
Essas arestas podem qualificar, por exemplo, a relação que as palavras têm em uma árvore de dependência. Outras representações de documentos podem usar arestas não direcionadas, principalmente para representar coocorrências de palavras.
Um grafo direcionado teria uma aparência um pouco diferente:
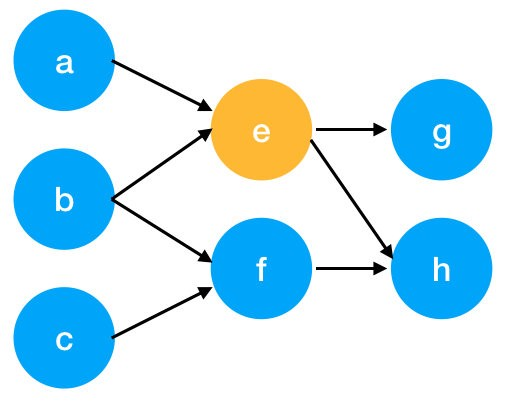
A ideia fundamental por trás da extração de palavras-chave por grafo é sempre a mesma: medir a importância de um vértice a partir de algumas informações obtidas a partir da estrutura do grafo.
Depois de criar um grafo, é hora de determinar como medir a importância dos vértices. Existem muitas opções. Alguns métodos escolhem medir o que é chamado de grau de um vértice (ou valência).
O grau (ou valência) de um vértice é igual ao número de arestas ou arcos que são direcionados para o vértice e o número de arestas saindo do vértice.
Outros métodos medem o número de vértices imediatos de um vértice dado ou um método bem conhecido no universo do SEO é o cálculo do PageRank deste grafo.
Independentemente da medida escolhida, você obterá uma pontuação para cada vértice. Essa pontuação determinará se deve ser escolhida como palavra-chave ou não.
Considere o seguinte texto como exemplo:
Após a invasão da base Stargate por extraterrestres, o coronel Jack O'Neill é chamado para ajudar. Stargate SG-1 é então formado e enviado para descobrir todos esses novos mundos.
🤖 Aprendizado de máquina
Os sistemas baseados em aprendizado de máquina podem ser usados para muitas tarefas de análise de texto, incluindo extração de palavras-chave. Mas o que é aprendizado de máquina? É um subdomínio da inteligência artificial que constrói algoritmos capazes de aprender e fazer previsões.[3]
Para processar dados textuais não estruturados, os sistemas de aprendizado de máquina precisam transformá-los em algo que possam entender. Mas como eles fazem isso? Transformando os dados em vetores (um conjunto de números com dados codificados), que contêm as diferentes características representativas de um texto.
Existem diferentes algoritmos e métodos de aprendizado de máquina que podem ser usados para extrair as palavras-chave mais relevantes de um texto, incluindo Support Vector Machines (SVM) e deep learning.
A seguir, apresentamos uma das abordagens mais comuns e eficazes para a extração de palavras-chave usando aprendizado de máquina:
Campos aleatórios condicionais
Os campos aleatórios condicionais (CRF) são uma abordagem estatística que aprende modelos ponderando diferentes características em uma sequência de palavras presentes em um texto. Essa abordagem considera o contexto e as relações entre as diferentes variáveis.
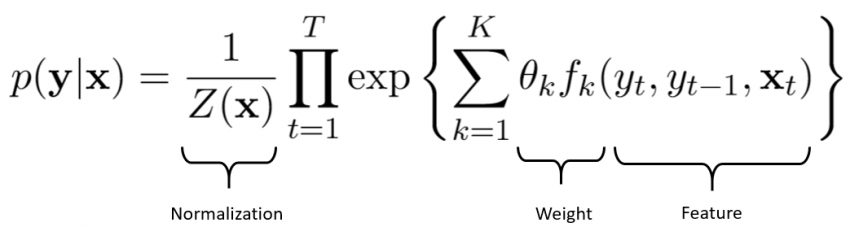
O uso de campos aleatórios condicionais permite criar modelos complexos e ricos. Outra vantagem dessa abordagem é sua capacidade de sintetizar informações. De fato, uma vez que o modelo foi treinado com exemplos, ele pode facilmente aplicar o que aprendeu a outros domínios.
No entanto, para usar campos aleatórios condicionais, você deve ter sólidas habilidades matemáticas que permitam calcular o ponderado de todas as características, e isso para todas as sequências de palavras.
O que o SEOQuantum usa para processar e extrair palavras-chave?
Uma abordagem híbrida entre aprendizado de máquina, informações linguísticas e estatísticas
Os métodos de extração de palavras-chave do SEOQuantum geralmente usam informações linguísticas. Não vamos descrever todos os elementos de informação que foram usados até agora, mas aqui estão alguns deles.
Às vezes, informações morfológicas ou sintáticas, como o tipo de palavra ou as relações entre as palavras em uma representação gramatical de dependência das frases, são usadas para determinar quais palavras-chave extrair. Em alguns casos, palavras pertencentes a certas classes de palavras obtêm pontuações mais altas (por exemplo, substantivos e grupos nominais), pois geralmente contêm mais informações sobre os textos do que palavras pertencentes a outras categorias.
Usamos marcadores discursivos (ou seja, frases que organizam o discurso em segmentos, como "no entanto" ou "além disso") ou ainda informações semânticas sobre as palavras (por exemplo, nuances de significado de uma palavra específica) com a integração do Word Embedding.
Na minha opinião, a maioria das ferramentas que usam informações do tipo linguístico obtém melhores resultados do que aquelas que não as usam.
Para obter melhores resultados na extração de palavras-chave relevantes de um texto, o SEOQuantum utiliza, portanto, um conceito misto de processamento linguístico, estatístico e aprendizado de máquina.
Conclusão
A melhor abordagem para você dependerá de suas necessidades, do tipo de dados que você processará e dos resultados que espera obter.
Agora que você conhece as diferentes opções disponíveis, é hora de colocar essas dicas em prática e descobrir todas as coisas emocionantes que você pode fazer com a extração de palavras-chave.
A extração de palavras-chave é uma excelente maneira de encontrar o que é relevante em grandes conjuntos de dados. Isso permite que pessoas que trabalham em todos os tipos de áreas automatizem processos complexos que, de outra forma, seriam extremamente demorados e ineficientes (e, em alguns casos, simplesmente impossíveis de serem realizados manualmente). Também fornece informações valiosas que podem ser usadas para tomar decisões melhores.
Quer programar por conta própria? Convido você a descobrir este notebook em Python: https://colab.research.google.com/drive/1Q4yorsQT6eVHmd8H07h7diinQEhCkyng.
🙏 Recursos utilizados para escrever este artigo
[1] https://fr.wikipedia.org/wiki/Topic_model#:~:text=En%20apprentissage%20automatique%20et%20en,th%C3%A8mes%20abstraits%20dans%20un%20document.
[2] https://hal.archives-ouvertes.fr/hal-00821671/document
[3] https://atlas.irit.fr/PIE/VSST/Actes-VSST2018-Toulouse/Ramiandrisoa.pdf
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: