Todas las herramientas de análisis semántico utilizan la extracción de palabras clave para crear guías de redacción. Utilizar el método de extracción adecuado según el objetivo permite encontrar los términos más relevantes para la redacción SEO.
La extracción de palabras clave (también llamada análisis de palabras clave) es un método de estudio de un texto que consiste en extraer automáticamente las palabras y términos más importantes. Esto permite resumir el contenido de un texto e identificar los principales temas que se abordan.
La extracción de palabras clave ayuda a los motores de búsqueda a analizar el contenido de las páginas en línea. Permite clasificar el conjunto de datos y definir las palabras que describen mejor cada página. Así, Google crea clusters (agrupaciones) de palabras clave, ahorrando muchas horas de procesamiento si tuviera que consultar la totalidad de su índice en cada búsqueda.
Una de las principales tareas del SEO consiste en determinar cuáles son las palabras clave estratégicas que queremos enfocar en nuestro sitio web, para poder crear contenido alrededor de estas palabras clave.
Este artículo utiliza ejemplos y referencias del universo Stargate SG-1 :)

❓ ¿Para qué sirve la extracción de palabras clave en SEO?
Hay al menos 3 buenas razones para buscar las palabras clave de una página.
- Conocer las opiniones
- Vigilar la competencia
- Encontrar nuevas ideas
1. Extraer las palabras clave y opiniones de una página
Captura de pantalla de la herramienta SEOQuantum
En primer lugar, vamos a estudiar la evaluación de una página sobre la serie Stargate. Gracias a la extracción de palabras clave, es fácil saber qué opiniones se mencionan (sólida; serie notable; prometedora...).
Puedes utilizar el software de SEOQuantum que permite extraer las palabras clave de un texto para encontrar palabras aisladas (palabras clave) o grupos de dos o más palabras que forman una frase (frases clave).
2. Vigilar la competencia
Hay una gran cantidad de herramientas disponibles para la búsqueda de palabras clave. Sin embargo, también puedes aprovechar la extracción de palabras clave para explorar automáticamente el contenido de los sitios web y extraer sus palabras clave más frecuentes. Si identificas las palabras clave más relevantes utilizadas por tus competidores, por ejemplo, puedes encontrar excelentes oportunidades para la redacción de contenido.
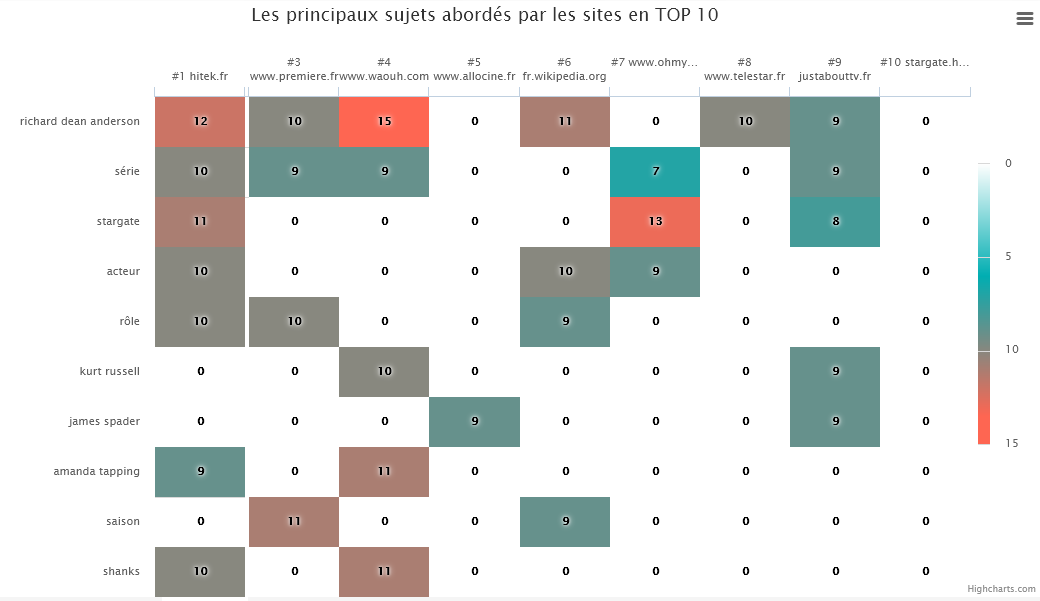
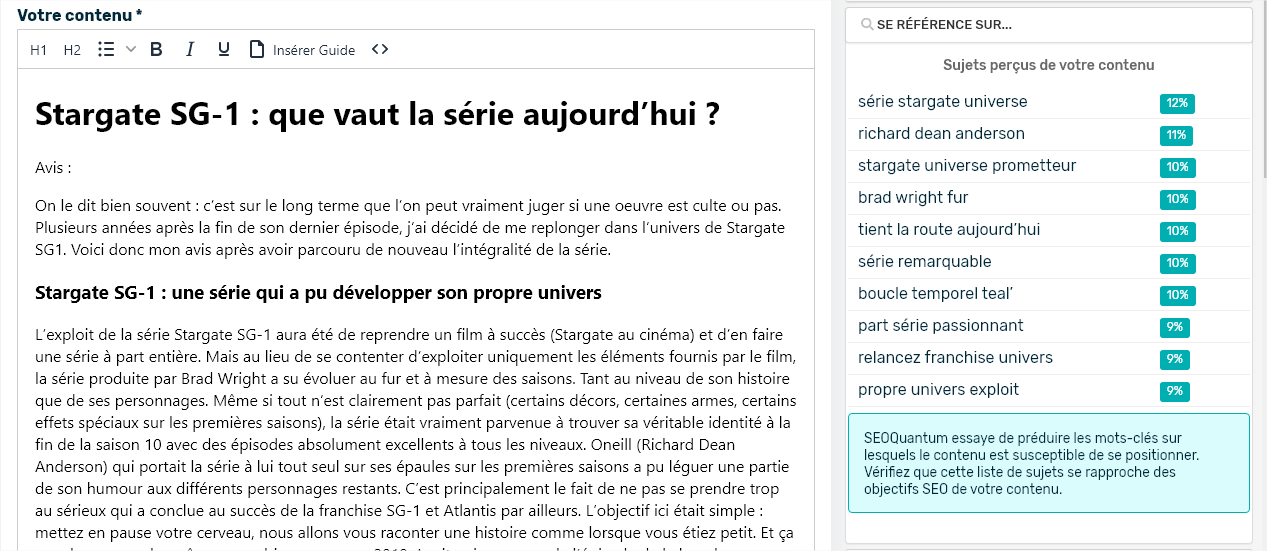
Gracias al análisis de la competencia de SEOQuantum, me encanta este gráfico (heatmap) que permite ver de un vistazo los temas abordados por los competidores en el TOP 10 de la SERP.
Aquí, para la consulta "actores stargate", notamos que:
- El primer sitio posicionado aborda principalmente la serie y los actores principales de la misma (Richard Dean Anderson, Amanda Tapping, Michael Shanks)
- Los otros temas de las páginas de la SERP están orientados hacia la serie o los actores de la primera película (Kurt Russel y James Spader).
3. Encontrar nuevas ideas de palabras clave
Las opiniones sobre los productos y otros tipos de contenido generado por los usuarios pueden ser excelentes fuentes para descubrir nuevas palabras clave. Extraer palabras clave para identificar las palabras clave estratégicas de los consumidores puede ser utilizado para fines de SEO mediante estrategias de long tail.
Como puedes ver, las palabras clave ya están presentes en el texto original. Esta es la principal diferencia entre la extracción de palabras clave y el modelado de temas[1], que consiste en elegir palabras clave de una lista de vocabulario o categorizar un texto en función de las palabras clave empleadas.
🤔 ¿Por qué es útil la extracción de palabras clave?
Si consideramos que más del 80% de los datos que generamos cada día no están estructurados, es decir, no están organizados de manera predefinida y, por lo tanto, son difíciles de analizar y procesar, la extracción de palabras clave es muy atractiva. Se trata de una herramienta poderosa que puede ayudar a comprender los datos relacionados con una página, opiniones de clientes, un comentario... En resumen, todos los datos no estructurados.
Entre las grandes ventajas de la extracción de palabras clave, podemos mencionar:
La escalabilidad
La extracción automatizada de palabras clave te permite analizar tantos datos como desees. Claro, podrías leer los textos tú mismo e identificar los términos clave manualmente, pero eso llevaría mucho tiempo. La automatización de esta tarea te da la libertad de concentrarte en otras tareas.
Criterios coherentes
La extracción de palabras clave actúa sobre la base de reglas y parámetros predefinidos. No obtendrás inconsistencias. Estas son frecuentes cuando el análisis del texto es manual.
Análisis en tiempo real
Puedes realizar una extracción de palabras clave en publicaciones de redes sociales, opiniones de clientes o tickets de solicitud de asistencia al cliente y así obtener información sobre lo que se dice de tu producto en tiempo real.
En resumen...
La extracción de palabras clave permite extraer lo que es relevante de una gran cantidad de datos no estructurados. Al extraer palabras o frases clave, podrás hacerte una idea de las palabras más importantes de un texto y los temas abordados.
Ahora que conoces el concepto de extracción de palabras clave y tienes una buena comprensión de su uso, es hora de entender cómo funciona. La siguiente sección explica los principios fundamentales de la extracción de palabras clave y te presenta los diferentes enfoques de este método, incluyendo estadísticas, lingüística y aprendizaje automático.
🔎 ¿Cómo funciona la extracción de palabras clave?
La extracción de palabras clave permite identificar fácilmente las palabras y frases relevantes de un texto no estructurado. Esto incluye páginas web, correos electrónicos, publicaciones en redes sociales, conversaciones de mensajería instantánea, así como cualquier otro tipo de datos que no estén organizados de manera predefinida.
Hay diferentes métodos que puedes utilizar para extraer automáticamente las palabras clave. Desde enfoques estadísticos simples que detectan las palabras clave contando la frecuencia de las palabras, hasta enfoques más avanzados posibles gracias al aprendizaje automático, podrás implementar el modelo que se ajuste a tus necesidades.
En esta sección, examinaremos los diferentes enfoques de la extracción de palabras clave, centrándonos en los modelos basados en el aprendizaje automático.[2]
Enfoques estadísticos simples
El uso de estadísticas es uno de los métodos más simples para identificar las palabras y expresiones clave de un texto.
Hay diferentes tipos de enfoques estadísticos, incluyendo la frecuencia de palabras, las colocaciones de palabras y las coocurrencias, el TF-IDF (del inglés term frequency-inverse document frequency) y el RAKE (Rapid Automatic Keyword Extraction).
Estos enfoques no requieren datos de aprendizaje para extraer las palabras clave más importantes de un texto. Sin embargo, dado que se basan en estadísticas, pueden pasar por alto palabras o frases relevantes que solo se mencionan una vez. Examinemos más de cerca estos diferentes enfoques:
La frecuencia de palabras
La frecuencia de palabras consiste en enumerar las palabras y frases que aparecen con más frecuencia en un texto. Esto puede ser muy útil para múltiples propósitos, desde la identificación de términos recurrentes en una serie de evaluaciones de productos hasta la búsqueda de los problemas más comunes en las interacciones con el servicio al cliente.
Sin embargo, los enfoques que se basan en la frecuencia de palabras consideran los documentos como una simple "colección de palabras", dejando de lado aspectos cruciales relacionados con la semántica, la estructura, la gramática y el orden de las palabras. Los sinónimos, por ejemplo, no pueden ser detectados por este método.
Aquí hay un extracto del código Python para obtener la frecuencia de palabras en un texto (puedes encontrar el cuaderno más abajo):
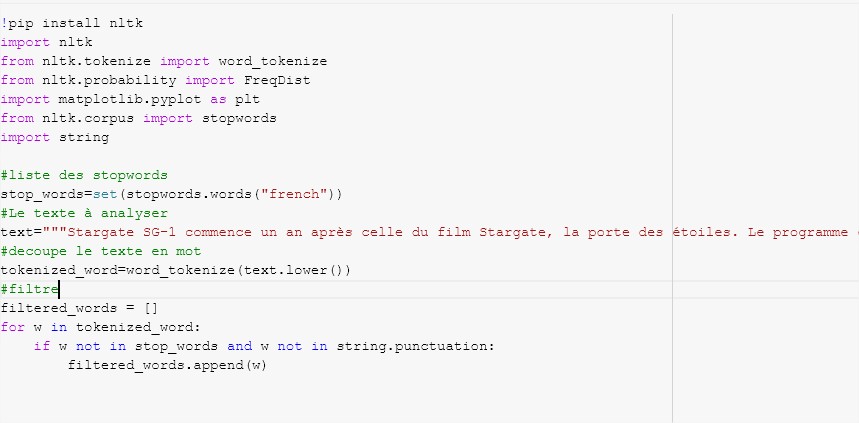

Colocaciones y coocurrencias de palabras
También conocidas como n-gramas, las colocaciones de palabras y las coocurrencias pueden ayudarte a comprender la estructura semántica de un texto. Estos métodos consideran cada palabra como única.
Diferencias entre colocaciones y coocurrencias:
Las colocaciones son palabras que a menudo se asocian. Los tipos de colocaciones más comunes son los bigramas (dos términos que aparecen de manera adyacente, como "redacción web" o "agencia digital") y los trigramas (un grupo de tres palabras, como "fácil de usar" o "transporte público").
Las coocurrencias, por otro lado, se refieren a palabras que tienden a coexistir en el mismo texto. No necesariamente tienen que ser adyacentes, pero tienen una relación semántica.

El TF-IDF
TF-IDF es la abreviatura del inglés frequency-inverse document frequency, una fórmula que mide la importancia de una palabra que aparece en un documento que forma parte de un corpus. Esta medida calcula el número de veces que una palabra aparece en un texto (term frequency) y lo compara con el inverso de la proporción de documentos del corpus que contienen el término (es decir, la rareza o frecuencia de esa palabra).
Al multiplicar estas dos cantidades, se obtiene un puntaje TF-IDF. Cuanto mayor sea el puntaje, más relevante será la palabra para el documento.
En cuanto a la extracción de palabras clave, esta medida puede ayudarte a identificar las palabras más relevantes de un contenido (aquellas que obtuvieron los mejores puntajes) y considerarlas como palabras clave. Esto puede ser especialmente útil para tareas como el etiquetado de tickets de soporte técnico o el análisis de comentarios de clientes.
En la mayoría de estos casos, las palabras que aparecen con más frecuencia en un conjunto de documentos no son necesariamente las más relevantes. Del mismo modo, una palabra que aparece en un texto único, pero que no aparece en otros documentos, puede ser muy importante para comprender el contenido de ese texto.
¿TF IDF para SEO?
Los motores de búsqueda a veces utilizan el modelo TF-IDF en complemento con otros factores.
¿El método TF-IDF proporciona suficiente información para optimizar tus redacciones de contenido? En absoluto.
Esta metodología tiene más de 50 años y juega un papel muy limitado en el funcionamiento de los algoritmos de búsqueda de Google. No es una tecnología de vanguardia.
RAKE
El Rapid Automatic Keyword Extraction (RAKE) es un método bien conocido de extracción de palabras clave que utiliza una lista de palabras vacías (stopwords) y frases que actúan como "delimitadores" para detectar las palabras o frases más relevantes en un texto.
Toma el siguiente texto como ejemplo:
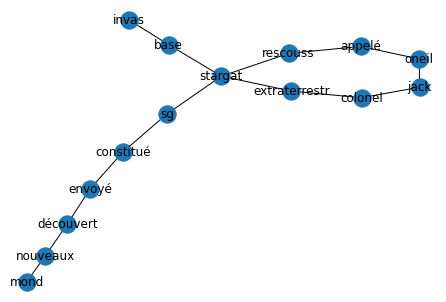
Tras la invasión de la base Stargate por extraterrestres, el coronel Jack O'Neill es llamado al rescate. Stargate SG-1, entonces se forma y es enviado a descubrir todos estos nuevos mundos.
Lo primero que hace el método es dividir el texto en una lista de palabras y eliminar las palabras vacías de esa lista. El resultado es una lista que contiene lo que se llama palabras de contenido.
Supongamos que nuestra lista de palabras clave y frases es la siguiente:
stopwords = [tras, de, la, por, el, es, no, si, él, de, tú, a, las, uno, ellas, ….]
Nuestra lista de 8 palabras de contenido se verá así:
palabras_contenido = [Invasión, base, stargate, extraterrestre, coronel, Jack Oneill, llamado, rescate, Stargate, SG1, constituido, enviado, descubrimiento, nuevos, mundos,…] con el delimitador siendo la coma o el punto.
A continuación, el algoritmo divide el texto en función de las frases y las palabras vacías para crear expresiones. En nuestro caso, las frases clave serían las siguientes:
Tras la invasión de la base Stargate por extraterrestres, el coronel Jack ONeill es llamado al rescate. Stargate SG-1, entonces se forma y es enviado a descubrir todos estos nuevos mundos.
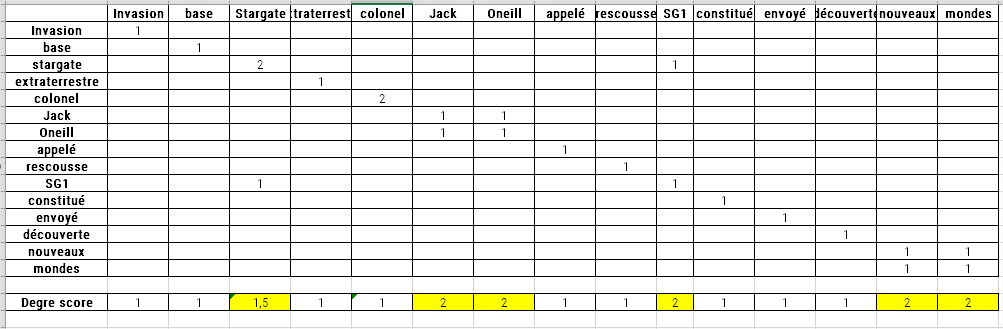
Después de dividir el texto de esta manera, el algoritmo crea una tabla de coocurrencias de palabras. Cada fila indica el número de veces que una palabra de contenido dada coexiste con otra palabra de contenido.
Una vez construida esta tabla, las palabras se califican. Las calificaciones corresponden a la cantidad de apariciones de una palabra en la tabla (es decir, la suma del número de coocurrencias de la palabra con cualquier otra palabra de contenido). Por lo tanto, se trata de la frecuencia de la palabra (es decir, la cantidad de veces que la palabra aparece en el texto).
Si dividimos el grado dividido por la frecuencia de cada una de las palabras de nuestro ejemplo, obtendríamos:
Si dos palabras o frases clave aparecen juntas en el mismo orden más de dos veces, se crea una nueva frase clave, independientemente de la cantidad de palabras vacías que contenga. La calificación de esta frase clave se tiene en cuenta de la misma manera que la de las frases clave únicas.
Se selecciona una palabra clave o una frase clave cuando su calificación está entre las T mejores calificaciones, siendo T el número de palabras clave que deseas extraer.
Ejemplo con RAKE NLTK
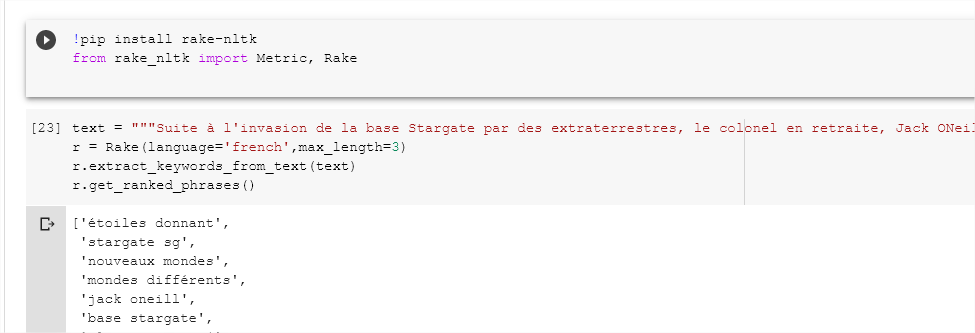
RAKE NLTK es una implementación específica de Python del algoritmo RAKE (Rapid Automatic Keyword Extraction) que utiliza NLTK debajo del capó. Esto facilita su uso para otras tareas de análisis de texto.
Enfoques basados en la teoría de grafos
Un grafo puede definirse como un conjunto de vértices con conexiones entre ellos. Un texto se representa entonces como un grafo de diferentes maneras. Las palabras pueden considerarse como vértices que están conectados por un enlace dirigido (es decir, una conexión unidireccional entre los vértices).
Estos enlaces pueden calificar, por ejemplo, la relación que las palabras tienen en un árbol de dependencia. Otras representaciones de documentos pueden utilizar enlaces no dirigidos, especialmente para representar coocurrencias de palabras.
Un grafo dirigido tendría un aspecto un poco diferente:
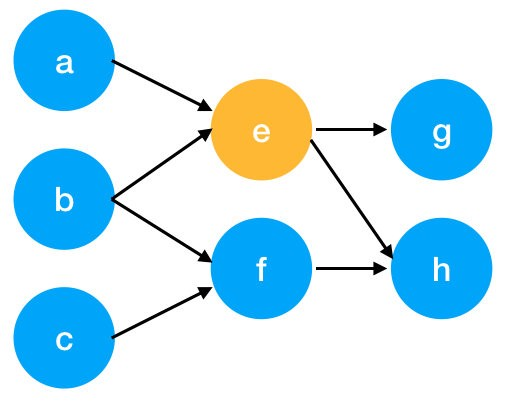
La idea fundamental detrás de la extracción de palabras clave por grafo es siempre la misma: medir la importancia de un vértice a partir de cierta información obtenida a partir de la estructura del grafo.
Una vez que hayas creado un grafo, es hora de determinar cómo medir la importancia de los vértices. Hay muchas opciones. Algunos métodos eligen medir lo que se llama el grado de un vértice (o valencia).
El grado (o valencia) de un vértice es igual al número de enlaces o arcos que se dirigen hacia el vértice y el número de enlaces que salen del vértice.
Otros métodos miden el número de vértices inmediatos de un vértice dado o bien un método bien conocido en el universo del SEO es el cálculo del PageRank de este grafo.
Independientemente de la medida elegida, obtendrás una calificación para cada vértice. Esta última determinará si debe ser elegido como palabra clave o no.
Toma el siguiente texto como ejemplo:
Tras la invasión de la base Stargate por extraterrestres, el coronel Jack O'Neill es llamado al rescate. Stargate SG-1, entonces se forma y es enviado a descubrir todos estos nuevos mundos.
🤖 Aprendizaje automático
Los sistemas basados en aprendizaje automático pueden utilizarse para muchas tareas de análisis de texto, incluida la extracción de palabras clave. Pero, ¿qué es el aprendizaje automático? Es un subdominio de la inteligencia artificial que construye algoritmos capaces de aprender y hacer predicciones.[3]
Para procesar datos textuales no estructurados, los sistemas de aprendizaje automático deben transformarlos en algo que puedan entender. Pero, ¿cómo lo logran? Transformando los datos en vectores (un conjunto de números con datos codificados) que contienen las diferentes características representativas de un texto.
Hay diferentes algoritmos y métodos de aprendizaje automático que pueden utilizarse para extraer las palabras clave más relevantes de un texto, incluyendo Support Vector Machines (SVM) y el deep learning.
A continuación, se presenta uno de los enfoques más comunes y efectivos para la extracción de palabras clave utilizando el aprendizaje automático:
Campos aleatorios condicionales
Los campos aleatorios condicionales (CRF) son un enfoque estadístico que aprende modelos ponderando diferentes características en una secuencia de palabras presentes en un texto. Este enfoque tiene en cuenta el contexto y las relaciones entre las diferentes variables.
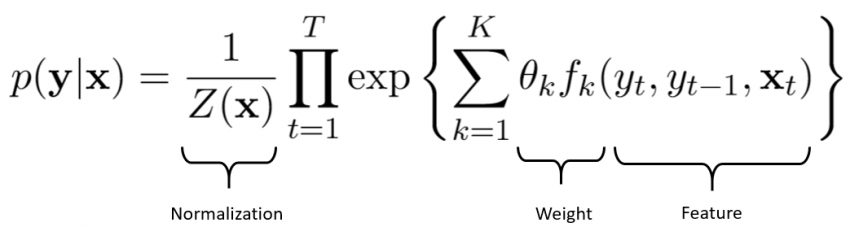
El uso de campos aleatorios condicionales te permite crear modelos complejos y ricos. Otra ventaja de este enfoque es su capacidad para sintetizar información. De hecho, una vez que el modelo ha sido entrenado con ejemplos, puede aplicar fácilmente lo que ha aprendido a otros dominios.
Sin embargo, para utilizar campos aleatorios condicionales, debes tener sólidas habilidades matemáticas que te permitan calcular la ponderación de todas las características, y esto, para todas las secuencias de palabras.
Conclusión
El mejor enfoque para ti dependerá de tus necesidades, del tipo de datos que procesarás y de los resultados que esperas obtener.
Ahora que conoces las diferentes opciones disponibles, es hora de que pongas en práctica estos consejos y descubras todas las cosas emocionantes que puedes hacer con la extracción de palabras clave.
La extracción de palabras clave es una excelente manera de encontrar lo que es relevante en grandes conjuntos de datos. Esto permite a las personas que trabajan en todo tipo de campos automatizar procesos complejos que, de lo contrario, serían extremadamente largos e ineficientes (y, en algunos casos, simplemente imposibles de realizar manualmente). También proporciona información valiosa que puede ser utilizada para tomar mejores decisiones.
¿Quieres programar por ti mismo? Te invito a descubrir este cuaderno en Python: https://colab.research.google.com/drive/1Q4yorsQT6eVHmd8H07h7diinQEhCkyng.
🙏 Recursos utilizados para escribir este artículo
[1] https://fr.wikipedia.org/wiki/Topic_model#:~:text=En%20apprentissage%20automatique%20et%20en,th%C3%A8mes%20abstraits%20dans%20un%20document.
[2] https://hal.archives-ouvertes.fr/hal-00821671/document
[3] https://atlas.irit.fr/PIE/VSST/Actes-VSST2018-Toulouse/Ramiandrisoa.pdf
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: