Prólogo: en el universo de las herramientas SEO, la competencia es feroz. Muchos detractores, colegas y competidores se adelantan a los métodos y tecnologías utilizados por la plataforma SEOQuantum sin conocer nuestros algoritmos. Este artículo revela una parte de nuestro secreto industrial. Disfruta :-)
Crear contenidos de calidad y relevantes con respecto a las palabras clave en las que quieres clasificar es esencial. Sin embargo, la relevancia del contenido es más difícil de evaluar. Los días en que se podía engañar a un motor de búsqueda haciéndole creer que el contenido estaba relacionado con un tema llenando las páginas y las etiquetas con tantas palabras clave, coocurrencias y sinónimos como fuera posible, han quedado atrás.
Google mejora continuamente su capacidad para entender el comportamiento humano y el lenguaje. La capacidad del motor de búsqueda para entender y analizar las intenciones de búsqueda de los usuarios es mejor que nunca. Por lo tanto, es esencial mejorar nuestra capacidad para medir la relevancia con el fin de crear contenido que Google perciba como realmente útil, y por lo tanto, más digno de ser bien referenciado.
Nuestra herramienta de verificación de la relevancia del contenido
La inteligencia artificial al servicio del contenido. En 2018 aparece una nueva generación de modelos de IA, que permiten una representación de las palabras no sólo en función de su contexto general (las palabras con las que se utilizan frecuentemente en el corpus de entrenamiento), sino también en función de su contexto local (en una frase en particular). Se trata en particular del modelo llamado ELMo.

Sin embargo, ELMo no está diseñado para producir incrustaciones léxicas de frases, por lo que tuvimos que hacer evolucionar esta tecnología.
Hemos desarrollado a partir de este modelo una herramienta de evaluación de la relevancia del contenido que nos permite obtener una medida precisa de la relevancia en relación con una palabra clave, un tema o un concepto dado.
¿Qué son las incrustaciones léxicas?
Pero, ¿qué significa exactamente esto?
En 2013, un equipo de Google publicó un artículo describiendo un proceso de entrenamiento de modelos para enseñar a un algoritmo a entender cómo se representan las palabras en un espacio vectorial. Representar palabras o frases en un espacio vectorial de esta manera es lo que entendemos por word embedding (incrustaciones léxicas).
Desde la publicación del artículo, el concepto se ha convertido rápidamente en una forma muy popular de representar el contenido textual para cualquier tarea de aprendizaje automático en el campo del lenguaje natural. Ha permitido superar los límites en este sentido. La mejora de las capacidades de los asistentes personales virtuales como Alexa y Google Assistant está de hecho relacionada con la publicación de esta tecnología.
El término "espacio vectorial" es un enfoque matemático del procesamiento del lenguaje, lo entendemos aquí como un sistema de coordenadas multidimensional que nos permite modelar la relación de las palabras en función del contexto conceptual.
Imaginemos, por ejemplo, que queremos medir la similitud entre las siguientes cinco palabras:
- Plátano
- Kiwi
- Naranja
- Pimiento
- Cangrejo
La medida de la similitud semántica cuando el contexto conceptual es muy estrecho puede ser realizada de manera intuitiva.
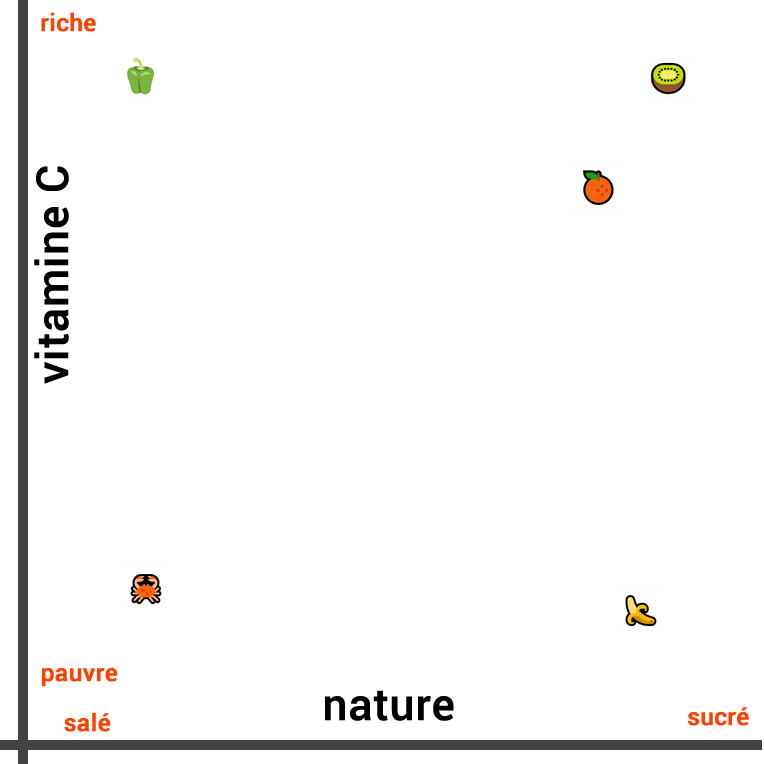
Así, si evaluamos las similitudes entre estos alimentos, en función de su naturaleza, podemos considerar que el plátano es muy similar a la naranja y al kiwi, ya que estos tres alimentos son frutas. Por otro lado, el pimiento y el cangrejo pueden ser considerados como menos similares (alimentos salados).
La representación visual de su similitud en función de su naturaleza se ve así:

Las tres frutas están cerca unas de otras, mientras que el vegetal está más alejado en una dirección y el cangrejo en la dirección opuesta.
Sin embargo, cuando medimos la similitud de estos alimentos en un contexto diferente, la representación cambia completamente. Si nos fijamos en la composición de vitamina C en lugar de su naturaleza, el kiwi y el pimiento son similares. Por otro lado, el plátano y el cangrejo no son ricos en vitamina C.
Por lo tanto, esta vez trazamos la siguiente línea:

También podemos crear una tercera línea que tenga en cuenta tanto la composición de vitamina C como la naturaleza del alimento (salado o dulce). Para ello, debemos representar los dos conceptos en dos dimensiones y visualizar la distancia entre ellos con un trazado en 2D:
Podemos calcular fácilmente la distancia entre estos puntos utilizando una fórmula simple.
¿Es esta una representación exacta de la similitud general de estas palabras?
Aunque esta tercera representación es la más precisa de las tres, todavía hay otros contextos conceptuales a tener en cuenta. Así, el cangrejo es un crustáceo mientras que los otros alimentos no lo son. Por lo tanto, sería aconsejable añadir una tercera dimensión. Aunque es posible crear una representación gráfica en tres dimensiones, esto sigue siendo difícil.
Añadir una cuarta dimensión es casi imposible. ELMo, por su parte, es capaz de representar el texto en un espacio vectorial de 512 dimensiones. Gracias a las matemáticas, podemos medir la similitud entre las palabras en muchas dimensiones.
El Word Embedding permite obtener resultados más precisos y tener en cuenta muchos conceptos diferentes. Los algoritmos pueden aprender a analizar un gran número de palabras en un espacio altamente dimensional, de modo que obtenemos una representación precisa de la "distancia" entre las palabras.
Hemos simplificado los mecanismos para hacer nuestra explicación más clara. La comprensión del incrustamiento de palabras y del aprendizaje del lenguaje natural es mucho más compleja.
En los modelos, los "ejes" no representan conceptos discernibles como es el caso en nuestro ejemplo anterior. Así, la medida de la similitud entre las palabras será diferente y es muy probable que los algoritmos se interesen por el ángulo entre los vectores.
Paso 1 - Extraer el contenido de una página web
Extraer el contenido de texto de una página web es una tarea ardua. Adoptar un enfoque determinista para la extracción de contenido es imposible. Los humanos, por otro lado, son capaces de hacerlo intuitivamente con mucha facilidad. De hecho, la mayoría de las personas son capaces de identificar qué texto es importante sin tener que leer el contenido de la página web gracias a las pistas visuales como el diseño de la página.
Google adopta un método similar en su forma de abordar el análisis de una página web:
Google tiene en cuenta su contenido no textual y la presentación visual general para decidir dónde aparecerá en los resultados de búsqueda. El aspecto visual de su sitio web nos ayuda a asimilar y entender sus páginas web.
Utilizando pistas visuales, Google está mejor equipado para entender el contenido que publicamos. Su comprensión es similar a la de un humano, ya que debe ser capaz de proporcionar contenidos que los humanos encuentren útiles y relevantes (en lugar de un contenido que satisfaga al máximo un modelo de relevancia dado).
¿Cómo extrae SEOQuantum el texto de una página?
Al elaborar una solución que se inspire en este enfoque, seríamos capaces de crear una herramienta escalable que resista la prueba del tiempo. Por lo tanto, decidimos abordar la tarea con el aprendizaje automático.
Hemos recopilado un gran número de páginas web para constituir un conjunto de datos. A partir de este conjunto, hemos entrenado una red neuronal para extraer la información de los contenidos.
Hemos entrenado esta herramienta para analizar varios elementos de cada bloque de texto (como su tamaño, su ubicación en la página web, el tamaño del texto, la densidad del texto, etc.) así como la imagen de la página entera (por ejemplo, el diseño visual y las características que los humanos y Google tienen en cuenta).
Ahora disponemos de una herramienta fiable capaz de predecir la probabilidad de que un bloque de texto dado sea considerado como parte del contenido de la página web.

Agregación de varias secciones de contenidos
Luego tuvimos que agregar los resultados de cada bloque de texto en una nota que tenga en cuenta las ponderaciones relativas a la importancia de cada bloque.
Hay dos formas diferentes de hacerlo:
- Calcular las medias ponderadas de todos los pasajes y luego medir sus distancias con respecto a la palabra clave objetivo
- Calcular la distancia entre cada bloque y la palabra clave, y luego hacer una media ponderada de todas las distancias.
Estas dos opciones no miden lo mismo. La primera mide la distancia entre el "contenido promedio" y el término de búsqueda, mientras que la segunda mide la distancia promedio entre cada elemento de contenido y la palabra clave.
Imagina que hemos extraído de una página web cuatro bloques de texto que, una vez integrados en nuestro espacio vectorial.
El primer método consiste en calcular la posición promedio de todos los contenidos integrados, y luego medirla en relación con la incrustación de los términos de búsqueda:
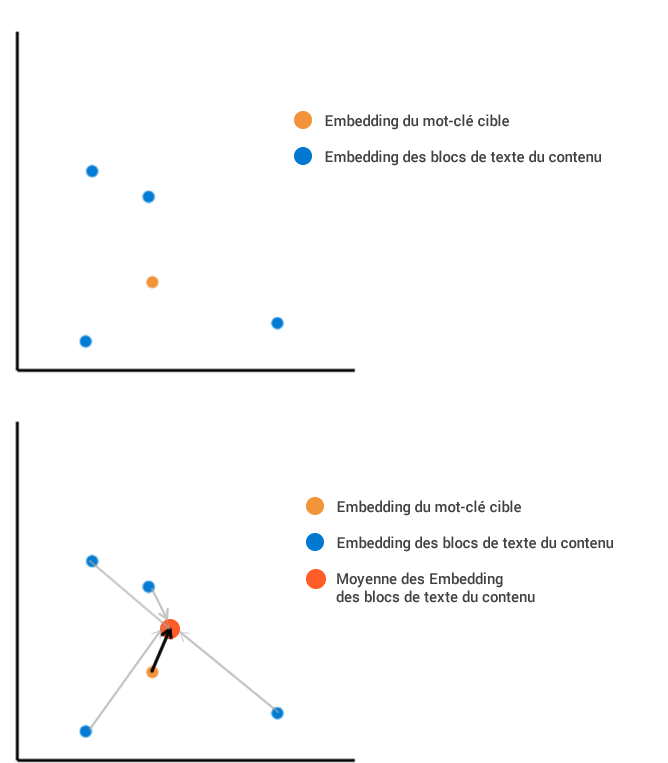
El segundo método consiste en calcular la distancia de cada bloque con respecto al término de búsqueda. Luego hacemos la media de todas estas diferentes longitudes, lo que da un resultado diferente. En este ejemplo, la distancia media de la longitud es mucho mayor con el segundo método que con el primero.
Paso 2 - ¿Cómo medir la relevancia del contenido?
El primer método intenta agregar todo el contenido de la página en un solo punto, independientemente de la diversidad de los bloques de contenido individuales entre sí, mientras que el segundo penaliza el contenido que es diverso y menos centrado en el término de búsqueda (incluso si la agregación de este contenido está muy cerca del término de búsqueda). Dado que cada método da un resultado diferente en términos de distancia, ¿cuál debemos usar?
El primer método es el más cercano a lo que queremos medir, es decir, la relevancia global del contenido. El segundo método consiste en examinar el grado de precisión del contenido, lo cual también puede ser útil. Decidimos que nuestra herramienta de relevancia de contenido (Puntuación Semántica de la herramienta) debería medir estos dos elementos y elegimos usar el primer método para medir la relevancia global y el segundo para medir la precisión del contenido.
Utilizando conceptos de normalización para convertir las distancias en porcentajes (donde el 100% representa una distancia nula y el 0% una distancia infinitamente grande), podemos medir tanto la distancia de relevancia como la distancia de precisión del contenido de una página web.
El hecho de obtener dos notas nos permite evaluar la utilidad del contenido caso por caso, teniendo en cuenta el tema y los términos de búsqueda. Sería lógico querer obtener dos notas tan altas como sea posible, sin embargo, una puntuación de precisión demasiado alta no siempre es necesaria. De hecho, la precisión de un contenido variará en función de la intención del usuario. Por ejemplo, un usuario que busca la expresión "Yoga" puede estar buscando información sobre las clases de Yoga y sobre los beneficios del Yoga, en cuyo caso el contenido que desea leer no está restringido.
¿Por qué usar nuestra herramienta de optimización de contenido?
Nuestra herramienta está disponible de forma gratuita en freetrial, por lo que puedes medir la relevancia de tu contenido web de forma independiente.
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: