Avant-propos : dans l’univers des outils SEO, la concurrence fait rage. De nombreux détracteurs, confrères, concurrents s’avancent sur les méthodes, technologies utilisées par la plateforme SEOQuantum sans connaitre nos algorithmes. Cet article lève le voile sur une partie de notre secret industriel. Enjoy :-)
Créer des contenus de qualité et pertinents à l’égard des mots-clés sur lesquels vous voulez vous classer est essentiel. La pertinence du contenu, quant à elle, est plus difficile à évaluer. L’époque où l’on pouvait tromper un moteur de recherche en lui faisant croire que le contenu était lié à un sujet en remplissant les pages et les balises avec autant de mots-clés, de cooccurrences et de synonymes que possible est révolue.
Google améliore continuellement sa capacité à comprendre le comportement humain ainsi que le langage. La capacité du moteur de recherche à comprendre et à analyser les intentions de recherches utilisateurs est meilleure que jamais. Il est donc primordial d’améliorer notre capacité à mesurer la pertinence afin de pouvoir créer un contenu que Google perçoit comme étant réellement utile, et donc plus digne d’être bien référencé.
Notre outil de vérification de la pertinence du contenu
L’intelligence artificielle au service du contenu. En 2018 apparaît une nouvelle génération de modèles d’IA, permettant une représentation des mots non seulement en fonction de leur contexte général (les mots avec lesquels ils sont fréquemment employés dans le corpus d’entraînement), mais aussi en fonction de leur contexte local (dans une phrase en particulier). Il s’agit notamment du modèle appelé ELMo.

ELMo n’est toutefois pas prévu pour produire des plongements lexicaux de phrases, nous avons dû faire évoluer cette technologie.
Nous avons développé à partir de ce modèle un outil d’évaluation de la pertinence du contenu qui nous permet d’obtenir une mesure précise de la pertinence par rapport à un mot-clé, un sujet ou un concept donné.
Que sont les plongements lexicaux ?
Mais qu’est-ce que cela signifie exactement ?
En 2013, une équipe de Google a publié un article décrivant un processus d’entraînement de modèles pour apprendre à un algorithme à comprendre comment les mots sont représentés dans un espace vectoriel. Représenter des mots ou des phrases dans un espace vectoriel de cette manière est ce que nous entendons par le word embedding (plongements lexicaux).
Depuis la publication de l’article, le concept est rapidement devenu un moyen très populaire de représenter le contenu textuel pour toute tâche d’apprentissage automatique dans le domaine du langage naturel. Il a permis de repousser les limites à cet égard. L’amélioration des capacités des assistants personnels virtuels tels qu’Alexa et Google Assistant est d’ailleurs liée à la publication de cette technologie.
Le terme « espace vectoriel » est une approche mathématique du traitement du langage, nous l’entendons ici comme un système multidimensionnel de coordonnées qui nous permet de modéliser la relation des mots en fonction du contexte conceptuel.
Imaginons par exemple que nous souhaitions mesurer la similarité entre les cinq mots suivants :
- Banane
- Kiwi
- Orange
- Poivron
- Crabe
La mesure de la similarité sémantique lorsque le contexte conceptuel est très étroit peut être effectuée de manière intuitive.
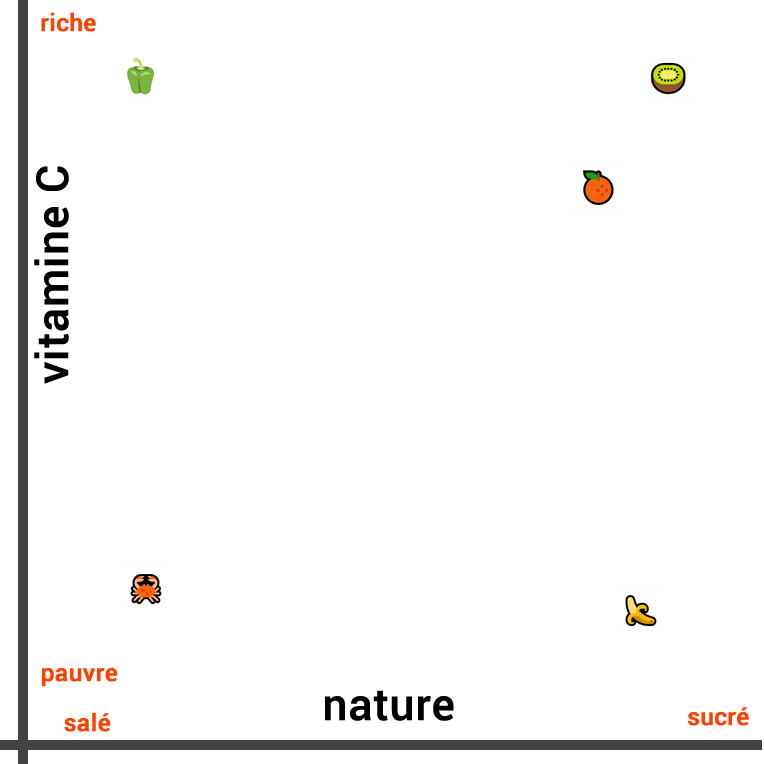
Ainsi, si nous évaluons les similarités entre ces aliments, en fonction de leur nature, nous pouvons considérer que la banane est très semblable à l’orange et au kiwi, car ces trois aliments sont des fruits. En revanche, le poivron et le crabe peut être considérés comme étant moins similaires (aliments salés).
La représentation visuelle de leur similarité en fonction de leur nature ressemble à ceci :

Les trois fruits sont proches les uns des autres alors que le légume est plus éloigné dans une direction et le crabe dans la direction opposée.
Cependant, lorsque nous mesurons la similarité de ces aliments dans un contexte différent, la représentation change complètement. Si l’on s’intéresse à la composition en vitamine C plutôt qu’à leur nature, le kiwi et le poivron sont semblables. En revanche, la banane, le crabe ne sont pas riches en vitamine C.
Donc, cette fois-ci, nous traçons la ligne suivante :

Nous pouvons également créer une troisième ligne qui tienne compte à la fois de la composition en vitamine C et de la nature de l’aliment (salé ou sucré). Pour cela il faut représenter les deux concepts en deux dimensions et en visualisant la distance entre eux avec un tracé en 2D :
Nous pouvons facilement calculer la distance entre ces points en utilisant une formule simple.
S’agit-il d’une représentation exacte de la similarité générale de ces mots ?
Bien que cette troisième représentation soit la plus précise des trois, il existe encore d’autres contextes conceptuels à prendre en compte. Ainsi le crabe est un crustacé alors que les autres aliments ne le sont pas. Il serait donc judicieux d’ajouter une troisième dimension. S’il est possible de créer une représentation graphique en trois dimensions, cela reste difficile.
Ajouter une quatrième dimension est presque impossible. ELMo quant à lui est capable de représenter le texte dans un espace vectoriel à 512 dimensions. C’est grâce aux mathématiques que nous pouvons mesurer la similarité entre les mots sur de nombreuses dimensions.
Le Word Embedding permet donc d’obtenir des résultats plus précis et de prendre en compte de nombreux concepts différents. Les algorithmes peuvent apprendre à analyser un nombre important de mots dans un espace hautement dimensionnel, de sorte que nous obtenons une représentation précise de la « distance » entre les mots.
Nous avons simplifié les mécanismes de manière à rendre notre explication plus claire. La compréhension du plongement de mots et de l’apprentissage du langage naturel est beaucoup plus complexe.
Dans les modèles, les « axes » ne représentent pas des concepts discernables comme c’est le cas dans notre exemple ci-dessus. Ainsi, la mesure de la similarité entre les mots sera différente et il y a de fortes chances que les algorithmes s’intéressent à l’angle entre les vecteurs.
Etape 1 - Extraire le contenu d’une page Web
Extraire le contenu texte d’une page web est une tâche ardue. Adopter une approche déterministe de l’extraction de contenu est impossible. Les humains, en revanche, sont capables de le faire intuitivement très facilement. En effet, la plupart des gens sont capables d’identifier quel texte est important sans avoir à lire le contenu de la page Web grâce à des repères visuels tels que la mise en page.
Google adopte une méthode similaire dans sa façon d’aborder l’analyse d’une page Web :
Google tient compte de votre contenu non textuel ainsi que de la présentation visuelle globale pour décider où vous apparaîtrez dans les résultats de recherche. L’aspect visuel de votre site Web nous aide à assimiler, à comprendre vos pages Web.En utilisant des repères visuels, Google est mieux à même de comprendre le contenu que nous publions. Sa compréhension est similaire à celle d’un humain, car il doit être capable de fournir des contenus que les humains trouvent utiles et pertinents (plutôt qu’un contenu qui satisfait au mieux un modèle de pertinence donné).
Comment SEOQuantum extrait le texte d’une page ?
En élaborant une solution qui s’inspire de cette approche, nous serions en mesure de créer un outil évolutif qui résiste à l’épreuve du temps. Nous avons donc décidé d’aborder la tâche à l’aide de l’apprentissage automatique.
Nous avons rassemblé un grand nombre de pages Web de manière à constituer un ensemble de données. À partir de cet ensemble, nous avons entraîné un réseau neuronal à extraire les informations de contenus.
Nous avons entraîné cet outil à analyser plusieurs éléments de chaque bloc de texte (tels que sa taille, son emplacement sur la page Web, la taille du texte, la densité du texte, etc.) ainsi que de l’image de la page entière (par exemple la disposition visuelle et les caractéristiques que les humains et Google prennent en compte).
Nous disposons désormais d’un outil fiable capable de prédire la probabilité qu’un bloc de texte donné soit considéré comme faisant partie du contenu de la page Web.

Agrégation de plusieurs sections de contenus
Nous avons ensuite dû agréger les résultats de chaque bloc de texte en une note tenant compte des pondérations relatives à l’importance de chaque bloc.
Il y a deux façons différentes de le faire :
- Calculer les moyennes pondérées de tous les passages et mesurer ensuite leurs distances vis-à-vis du mot-clé visé
- Calculer la distance entre chaque bloc et le mot-clé, puis faites une moyenne pondérée de toutes les distances.
Ces deux options ne mesurent pas la même chose. La première mesure la distance entre le « contenu moyen » et le terme de recherche, tandis que la seconde mesure la distance moyenne entre chaque élément de contenu et le mot-clé.
Imaginez que nous ayons extrait d’une page Web quatre blocs de texte qui, une fois intégrés dans notre espace vectoriel.
La première méthode consiste à calculer la position moyenne de tous les contenus intégrés, puis à la mesurer par rapport au plongement des termes de recherche :
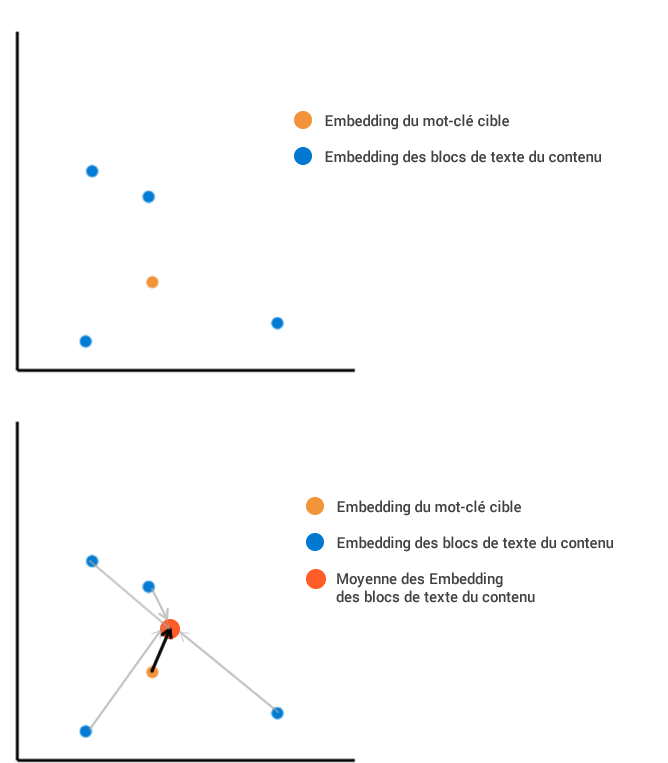
La deuxième méthode consiste à calculer la distance de chaque bloc par rapport au terme de recherche. Nous faisons ensuite la moyenne de toutes ces différentes longueurs, ce qui donne un résultat différent. Dans cet exemple, la distance moyenne de la longueur est beaucoup plus grande avec la deuxième méthode qu’avec la première.
Etape 2 - Mesurer la pertinence du contenu ?
La première méthode tente d’agréger l’ensemble du contenu de la page en un seul point, quelle que soit la diversité des blocs de contenu individuels les uns par rapport aux autres, tandis que la seconde pénalise le contenu qui est diversifié et moins centré sur le terme de recherche (même si l’agrégation de ce contenu est très proche du terme de recherche). Puisque chaque méthode donne un résultat différent en termes de distance, laquelle devons-nous utiliser ?
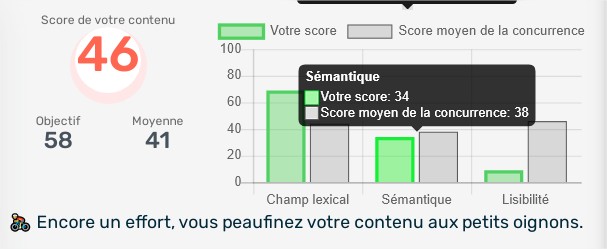
La première méthode est la plus proche de ce que nous voulons mesurer, à savoir la pertinence globale du contenu. La deuxième méthode consiste à examiner le degré de précision du contenu, ce qui peut aussi s’avérer utile. Nous avons décidé que notre outil de pertinence du contenu (Score Sémantique de l’outil) devrait mesurer ces deux éléments et avons choisi d’utiliser la première méthode pour mesurer la pertinence globale et la seconde pour mesurer la précision du contenu.
En utilisant des concepts de normalisation pour convertir les distances en pourcentage (où 100 % représentent une distance nulle et 0 % une distance infiniment grande), nous pouvons mesurer à la fois la distance de pertinence et la distance de précision du contenu d’une page Web.
Le fait d’obtenir deux notes nous permet d’évaluer l’utilité du contenu au cas par cas, en tenant compte du sujet et des termes de recherche. Il serait logique de vouloir obtenir deux notes aussi élevées que possible, pourtant un score de précision trop élevé n’est pas toujours nécessaire. En effet, la précision d’un contenu variera en fonction de l’intention de l’internaute. Par exemple, un internaute cherchant l’expression « Yoga » peut être à la recherche d’informations sur les cours de Yoga et sur les bénéfices du Yoga, auquel cas le contenu qu’il souhaite lire n’est pas restreint.
Pourquoi utiliser notre outil d’optimisation du contenu ?
Les outils de mesure de la pertinence des contenus disponibles sur le Web ne manquent pas. Cependant, nous n’en avons pas encore trouvé un qui tienne compte des plongements lexicaux des phrases ainsi que l’extraction de texte du contenu de façon performante.
Notre outil est disponible gratuitement en freetrial, vous pouvez donc mesurer la pertinence de votre contenu Web de manière indépendante.
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: